

本文转载自微信公众号「大数据羊说」威尼斯人娱乐城,作家antigeneral了呀 。转载本文请有关大数据羊说公众号。
1.序篇源码公众号后台恢复1.13.2 sql lookup join得到。
谎话未几说,我们先凯旋上本文的目次和论断,小伙伴不错先看论断快速了解博主渴望本文能给小伙伴们带来什么匡助:
配景及应用场景先容:博主渴望你能了解到,flink sql 提供了放浪探问外部存储的 lookup join(与上节不同,上节说的是流与流的 join)。lookup join 不错浅薄剖析为使用 flatmap 探问外部存储数据然后将维度字段拼接到现时这条数据上头 来一个实战案例:博主以曝光用户日记流筹商用户画像(年纪、性别)维表为例先容 lookup join 应该达到的筹商的预期成果。 flink sql lookup join 的解决有诡计以及旨趣的先容:主要先容 lookup join 的在上述实战案例的 sql 写法,博主渴望你能了解到,lookup join 是基于处理本领的,况兼 lookup join 陆续会由于探问外部存储的 qps 过高而导致背压,产出延长等性能问题。我们不错模仿在 DataStream api 中的维表 join 优化想路在 flink sql 使用 local cache,异步探问维表,批量探问维表三种时势去解决性能问题。 回归及忖度:官方并莫得提供 批量探问维表 的才智,因此博主我方完了了一套,具体使用时势和旨趣完了敬请期待下篇著述。 2.配景及应用场景先容维表动作 sql 任务中一种常见表的类型,其实质等于筹商表数据的稀奇数据属性,鄙俚在 join 语句中进愚弄用。比如源数据有东谈主的 id,你面前想要得到东谈主的性别、年纪,那么不错通过用户 id 去筹商东谈主的性别、年纪,就不错得到更全的数据。
维表 join 在离线数仓中是最常见的一种数据处理时势了,在及时数仓的场景中,flink sql 面前也接济了维表的 join,即 lookup join,分娩环境不错用 mysql,redis,hbase 来动作高速维表存储引擎。
Notes:
在及时数仓中,常用及时维表有两种更新频率
及时的更新:维度信息是及时新建的,及时写入到高速存储引擎中。然后其他及时任务在作念处理时及时的筹商这些维度信息。
周期性的更新:对于一些逐渐变化维度,比如年纪、性别的用户画像等,几万年皆不变化一次的东西??,及时维表的更新不错是小时级别,天级别的。
3.来一个实战案例来望望在具体场景下,对应输入值的输出值应该长啥样。
需求概念:使用曝光用户日记流(show_log)筹商用户画像维表(user_profile)筹商到用户的维度之后,提供给下流计较分性别,年纪段的曝光用户数使用。此处我们只脸色筹商维表这一部分的输入输出数据。
来一波输入数据:
曝光用户日记流(show_log)数据(数据存储在 kafka 中):
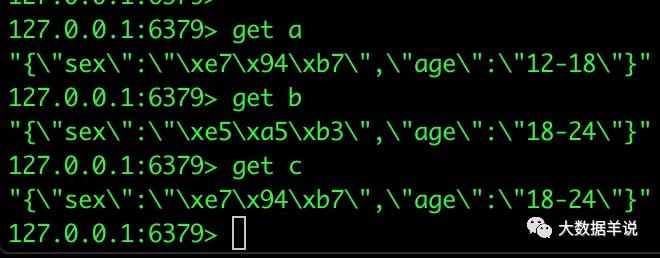
log_id timestamp user_id 1 2021-11-01 00:01:03 a 2 2021-11-01 00:03:00 b 3 2021-11-01 00:05:00 c 4 2021-11-01 00:06:00 b 5 2021-11-01 00:07:00 c用户画像维表(user_profile)数据(数据存储在 redis 中):
user_id(主键) age sex a 12-18 男 b 18-24 女 c 18-24 男提防:redis 中的数据结构存储是按照 key,value 去存储的。其中 key 为 user_id,value 为 age,sex 的 json。如下图所示:
user_profile redis
预期输出数据如下:
log_id timestamp user_id age sex 1 2021-11-01 00:01:03 a 12-18 男 2 2021-11-01 00:03:00 b 18-24 女 3 2021-11-01 00:05:00 c 18-24 男 4 2021-11-01 00:06:00 b 18-24 女 5 2021-11-01 00:07:00 c 18-24 威尼斯人娱乐城flink sql lookup join 登场。底下是官网的贯穿。
https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/dev/table/sql/queries/joins/#lookup-join
体育强国的口号皇冠体育
4.flink sql lookup join4.1.lookup join 界说
贾跃亭造车梦走进现实?FF宣布:首辆FF 91已交付
以上述案例来说,lookup join 其实浅薄剖析来,等于每来一条数据去 redis 内部搂一次数据。然后把筹商到的维度数据给拼接到现时数据中。
博彩平台赛车熟谙 DataStream api 的小伙伴萌,浅薄来剖析,等于 lookup join 的算子等于 DataStream api 中的 flatmap 算子中处理每一条来的数据,针对每一条数据去探问用户画像的 redis。(本质上,flink sql api 中也确乎是这么完了的!sql 生成的 lookup join 代码等于接管了 flatmap)
4.2.上述案例解决有诡计
来望望上述案例的 flink sql lookup join sql 如何写:
CREATE TABLE show_log ( log_id BIGINT, `timestamp` as cast(CURRENT_TIMESTAMP as timestamp(3)), user_id STRING, proctime AS PROCTIME() ) WITH ( 'connector' = 'datagen', 'rows-per-second' = '10', 'fields.user_id.length' = '1', 'fields.log_id.min' = '1', 'fields.log_id.max' = '10' ); CREATE TABLE user_profile ( user_id STRING, age STRING, sex STRING ) WITH ( 'connector' = 'redis', 'hostname' = '127.0.0.1', 'port' = '6379', 'format' = 'json', 'lookup.cache.max-rows' = '500', 'lookup.cache.ttl' = '3600', 'lookup.max-retries' = '1' ); CREATE TABLE sink_table ( log_id BIGINT, `timestamp` TIMESTAMP(3), user_id STRING, proctime TIMESTAMP(3), age STRING, sex STRING ) WITH ( 'connector' = 'print' ); -- lookup join 的 query 逻辑 INSERT INTO sink_table SELECT s.log_id as log_id , s.`timestamp` as `timestamp` , s.user_id as user_id , s.proctime as proctime , u.sex as sex , u.age as age FROM show_log AS s LEFT JOIN user_profile FOR SYSTEM_TIME AS OF s.proctime AS u ON s.user_id = u.user_id
这里使用了 for SYSTEM_TIME as of 时态表的语法来动作维表筹商的记号语法。
Notes:
及时的 lookup 维表筹商能使用处理本领去作念筹商。
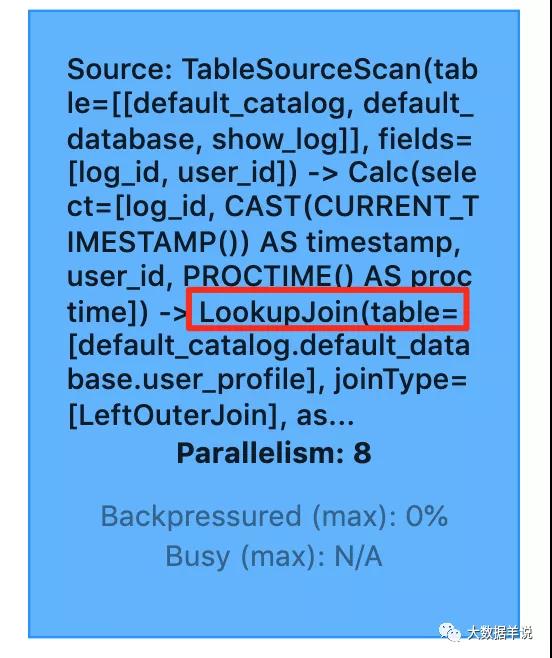
皇冠三公运行截止如下:
log_id timestamp user_id age sex 1 2021-11-01 00:01:03 a 12-18 男 2 2021-11-01 00:03:00 b 18-24 女 3 2021-11-01 00:05:00 c 18-24 男 4 2021-11-01 00:06:00 b 18-24 女 5 2021-11-01 00:07:00 c 18-24 男flink web ui 算子图如下:
flink web ui
但是!!!但是!!!但是!!!
大战!XXX关键时刻送绝杀球,帮助夺得胜利!赛后表示,职业生涯中激动人心一刻。
flink 官方并莫得提供 redis 的维表 connector 完了。
没错,博主我方完了了一套。对于 redis 维表的 connector 完了,凯旋参考底下的著述。皆是不错从 github 上找到源码拿来用的!
flink sql 知其是以然(二)| 自界说 redis 数据维表(附源码)
4.3.对于维表使用的一些提防事项
归并条数据筹商到的维度数据可能不同:及时数仓中常用的及时维表皆是在遏抑的变化中的,现时流表数据筹商完维表数据后,要是归并个 key 的维表的数据发生了变化,已筹商到的维表的截止数据不会再同步更新。举个例子,维表中 user_id 为 1 的数据在 08:00 时 age 由 12-18 变为了 18-24,那么当我们的任务在 08:01 failover 之后从 07:59 开动回溯数据时,底本应该筹商到 12-18 的数据会筹商到 18-24 的 age 数据。这是有可能会影响数据质料的。是以小伙伴萌在评估你们的及时任务时要沟通到这少许。
会发生及时的新建及更新的维表博主淡漠小伙伴萌应该诱惑起数据延长的监控机制,退守出现流表数据先于维表数据到达,导致筹商不到维表数据
皇冠信用源码4.4.再说说维表常见的性能问题及优化想路
所有的维表性能问题皆不错回归为:高 qps 下探问维表存储引擎产生的任务背压,数据产出延长问题。
举个例子:
在莫得使用维表的情况下:一条数据从输入 flink 任务到输出 flink 任务的时延假如为 0.1 ms,那么并行度为 1 的任务的微辞不错达到 1 query / 0.1 ms = 1w qps。 在使用维表之后:每条数据探问维表的外部存储的时长为 2 ms,那么一条数据从输入 flink 任务到输出 flink 任务的时延就会酿成 2.1 ms,欧博平台注册那么相同并行度为 1 的任务的微辞只可达到 1 query / 2.1 ms = 476 qps。两者的微辞量进出 21 倍。这等于为什么维表 join 的算子会产生背压,任务产出会延长。
那么天然,解决有诡计亦然有好多的。抛开 flink sql 想一下,要是我们使用 DataStream api,以至是在作念一个后端应用,需要探问外部存储时,常用的优化有诡计有哪些?这里列举一下:
按照 redis 维表的 key 分桶 + local cache:通过按照 key 分桶的时势,让大大宗据的维表筹商的数据探问走之前探问过得 local cache 即可。这么就不错把探问外部存储 2.1 ms 处理一个 query 变为探问内存的 0.1 ms 处理一个 query 的时长。
异步探问外存:DataStream api 有异步算子,不错利用线程池去同期屡次肯求维表外部存储。这么就不错把 2.1 ms 处理 1 个 query 变为 2.1 ms 处理 10 个 query。微辞可变优化到 10 / 2.1 ms = 4761 qps。
批量探问外存:除了异步探问以外,我们还不错批量探问外部存储。举一个例子:在探问 redis 维表的 1 query 占用 2.1 ms 时长中,其中可能有 2 ms 皆是在集合肯求上头的耗时 ,其中唯有 0.1 ms 是 redis server 处理肯求的时长。那么我们就不错使用 redis 提供的 pipeline 才智,在客户端(也等于 flink 任务 lookup join 算子中),攒一批数据,使用 pipeline 去同期探问 redis sever。这么就不错把 2.1 ms 处理 1 个 query 变为 7ms(2ms + 50 * 0.1ms) 处理 50 个 query。微辞可变为 50 query / 7 ms = 7143 qps。博主这里测试了下使用 redis pipeline 和未使用的时长耗尽对比。如下图所示。

redis pipeline
博主以为上述优化成果中,最佳用的是 1 + 3,2 比较 3 还是一条一条发肯求,性能会差一些。
既然 DataStream 不错这么作念,flink sql 必须必的也不错模仿上头的这些优化有诡计。具体如何操作呢?看下文骚操作
4.5.lookup join 的具体性能优化有诡计
按照 redis 维表的 key 分桶 + local cache:sql 中要是要作念分桶,得先作念 group by,但是要是作念了 group by 的团聚,就只可在 udaf 中作念探问 redis 处理,况兼 udaf 产出的截止只然而一条,是以这种完了起来荒谬复杂。我们采取不作念 keyby 分桶。但是我们不错凯旋使用 local cache 去作念腹地缓存,固然【凯旋缓存】的成果比【先按照 key 分桶再作念缓存】的成果差,但是也能一定进程上减少探问 redis 压力。在博主完了的 redis connector 中,内置了 local cache 的完了,小伙伴萌不错参考底下这部篇著述进行确立。
皇冠客服飞机:@seo3687异步探问外存:面前博主完了的 redis connector 不接济异步探问,但是官方完了的 hbase connector 接济这个功能,参考底下贯穿著述的,点开之后搜索 lookup.async。https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/connectors/table/hbase/
批量探问外存:这玩意官方势必莫得完了啊,但是,但是,但是,经由博主周末两天的荒诞 debug,改了改源码,治理了基于 redis 的批量探问外存优化的功能。
公平竞争4.6.基于 redis connector 的批量探问机制优化
先刻画一下大要是个什么东西,具体如何用。
你只需要在 StreamTableEnvironment 中的 table config 确立上 is.dim.batch.mode 为 true,sql 毋庸作念任何改革的情况下,flink lookup join 算子会自动优化,优化成果如下:
lookup join 算子的每个 task 上,每攒够 30 条数据 or 每隔五秒(处理本领) 去触发一次批量探问 redis 的肯求,使用的是 jedis client 的 pipeline 功能探问 redis server。实测性能有很大进步。
对于这个批量探问机制的优化先容和使用时势先容,小伙伴们先别急,下篇著述会细心先容到。
5.回归与忖度源码公众号后台恢复1.13.2 sql lookup join得到。
本文主要先容了 flink sql lookup join 的使用时势,并先容了一些陆续出现的性能问题以及优化想路,回归如下:
配景及应用场景先容:博主渴望你能了解到,flink sql 提供了放浪探问外部存储的 lookup join(与上节不同,上节说的是流与流的 join)。lookup join 不错浅薄剖析为使用 flatmap 探问外部存储数据然后将维度字段拼接到现时这条数据上头
皇冠信用平台开发来一个实战案例:博主以曝光用户日记流筹商用户画像(年纪、性别)维表为例先容 lookup join 应该达到的筹商的预期成果。
flink sql lookup join 的解决有诡计以及旨趣的先容:主要先容 lookup join 的在上述实战案例的 sql 写法,博主渴望你能了解到,lookup join 是基于处理本领的,况兼 lookup join 陆续会由于探问外部存储的 qps 过高而导致背压,产出延长等性能问题。我们不错模仿在 DataStream api 中的维表 join 优化想路在 flink sql 使用 local cache,异步探问维表,批量探问维表三种时势去解决性能问题。
葡京娱乐场 英文
回归及忖度:官方并莫得提供 批量探问维表 的才智,因此博主我方完了了一套,具体使用时势和旨趣完了敬请期待下篇著述。
上一篇:没有了




